Building a Clojure web app backed by Postgres
In this article, we’ll create a Clojure web app talking to a Postgres database. You should know, that I’m by no means an expert on the subject - this is just front-end developer exploring new areas. Big thanks to my friend Chris Wolfe who helped me understand a lot of concepts presented in this article (and was extremely patient at that).
The app
We’ll build a simple app for storing cooking recipes called NerdRecipes. I’ll continue working on the same concept app in future articles. You can find the final code for this part here: https://github.com/smogg/nerd-fitness. The app will be based on the simple Compojure template. The app will be talking to a Postgres database and it will have a few endpoints to save/fetch the recipes. It will be fully tested. In the future we will build authentication/authorization for our endpoints as well as the UI. The latter part most likely will be done in Reagent (with re-frame).
The beginning
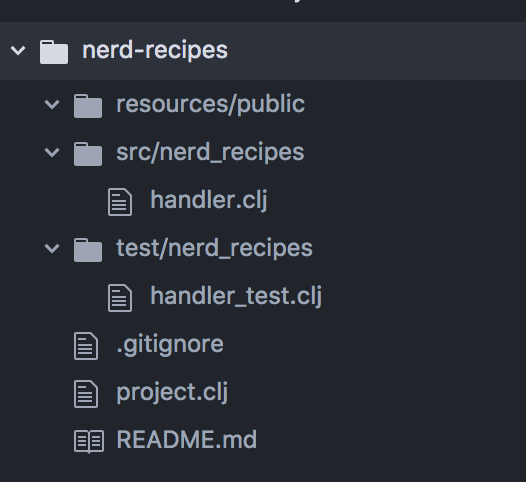
Let’s create a new project by running lein new compojure nerd-recipes. You should get a file structure similar to this:
The database
As mentioned earlier, we’ll use Postgres for our project. I won’t go into too much detail about setting up a database since a simple web search will reveal everything you need to know. I’m using Postgres app for Mac.
In Clojure, we’ll use jdbc.pool.c3p0 to set up a connection pool we’ll use for our app:
Update project.clj with above dependencies:
:
Let’s setup a database connection, create
; src/nerd-recipes/db.clj
As you can see, we’ve set up our connection to look for a database named nerd_recipes.
First, connect to the database from the command line using default Postgres user (or just double click postgres in Postgresapp I mentioned before):
psql -U postgres
Next, run some SQL statements to create a new database and a new user for our app:
;;ALL PRIVILEGES ON DATABASE nerd_recipes TO admin;
Let’s save above commands under dev/init_dev_db.sql for future use. You (or anyeone else) will be able to run the file using psql -U postgres -f dev/inti_dev_db.sql from the command line.
Let’s try our database connection in Clojure REPL:
=>nil=>nil=>=>=>=>
If everything went well you should see similar responses. We required java.jdbc and the connection pool we’ve set up previously in nerd-recipes.db. Then we used java.jdbc to create the test table, add an entry in the same table and then we verified that everything actually got saved to the database. Last but not least, we removed the same table and left the database as we’ve found it.
The SQL (hugging)
Running jdbc/db-do-commands with SQL strings in Clojure all the time is not pretty nor fun. Hugsql to the rescue - it will let you write plain SQL (with some additional helpers) and then automagically import those statements into your Clojure code (for example by defining functions in current namespace). It’s a great library with even better documentation that separates concerns you want separated.
Add [com.layerware/hugsql "0.4.8"] in your project.clj dependencies and create a new file under src/nerd_recipes/db/sql/recipes.sql. Next, add a few simple SQL statements for creating the recipes table, where we will store our app’s recipes. We are also creating a few handy statements we’ll use to create new or select recipes.
-- :name create-recipes-table :!NOT EXISTS recipes (id bigserial PRIMARY KEY,name varchar NOT NULL,description text NOT NULL,created_at timestamp NOT NULL default current_timestamp)-- :name drop-recipes-table :!IF EXISTS recipes-- :name insert-recipe :! :nINSERT INTO recipes (name, description)VALUES (:name, :description)-- :name recipe-by-name-like :? :1SELECT * FROM recipes WHERE name LIKE :name-like-- :name recipes-with-cols :? :*SELECT :i*:cols FROM recipes
Hugsql is gonna use the part after -- :name ... to define Clojure functions under the corresponding name. The :? or :! part tells hugsql what kind of result is expected.
For recipes-with-cols we used :* on the :name line, and :i:cols later, in the sql statement. This is literally expanding a Clojure collection (items will be separated by commas) inside your SQL. Neat! Refer to Hugsql docs to learn more about what just happened.
Let’s now make those functions available in Clojure:
Create a new file under src/nerd_recipes/db/recipes.clj
; src/nerd_recipes/db/recipes.clj
The def-db-fns macro is going to create functions in current namespace from SQL statements we defined before. The following functions should now be available:
nerd-recipes.db.recipes/create-recipes-tablenerd-recipes.db.recipes/drop-recipes-tablenerd-recipes.db.recipes/insert-recipenerd-recipes.db.recipes/recipe-by-name-likenerd-recipes.db.recipes/recipes-with-cols
Again, let’s make sure that everything is working as expected in the REPL:
=>nil=>=>1=>=>
Notice we no longer need java.jdbc to run the commands. You can remove it from your project’s dependencies as we’ll no longer be using it in this project.
Let’s also create another namespace to separate database functions from the rest of our application’s code:
; src/nerd-recipes/recipes.clj
This way you won’t have to think about database logic at all when creating/getting recipes elsewhere in your app.
The migrations
Next, let’s set up database migrations. We’ll use Drift - a simple, file-based migration library for Clojure similar to Rails. Add [drift "1.5.2"] in your :plugins and :dependencies sections inside project.clj.
By default, Drift will call the config.migrate-config/migrate-config function to get the settings map. Create that file and put some basic setup there:
; src/config/migrate_config.clj
Drift will look for migrations to run under the specified :directory and will rely on two functions - current-db-version and update-db-version to get current database version and update it respectively. We’ll store that information inside schema_migrations table, so let’s start by creating the corresponding .sql and .clj files (like we did in the previous step for recipes table). Let’s put the file under src/config/db/sql/schema_migrations.sql:
-- :name create-schema-migrations-table :!not exists schema_migrations (version integer not null,created_at timestamp not null default current_timestamp)-- :name current-db-version :? :1select * from schema_migrationsorder by created_at-- :name insert-db-version :! :ninsert into schema_migrations (version)values (:version)
src/config/db/schema_migrations.clj
We can now use the new namespace and write missing functions for config.migrate-config:
; src/config/migrate_config.clj
You’ll notice we also added two new keys to Drift settings - :init and :migration-number-generator. First one makes sure that schema_migrations table is present before we start migrating our database. The second one tells Drift which function to use when coming up with a new database version number. We used Drift’s built-in incremental-migration-number-generator which basically bumps the current version number by one.
You should now be able to run lein migrate to run the migrations. At the end of the process you should see a message similar to the following:
INFO: No changes were made to the database.
We don’t have any actual migrations written yet, so that’s expected. Let’s write one:
; src/migrations/001_create_tables.clj
Drift expects two functions to be present in a migration file - up and down. Running lein migrate now should create the tables. The process should end with a message similar to the following:
INFO: Migrated to version: 1
You can double check that database migration was properly recorded in schema_migrations table from the command line:
$ psql nerd_recipes -U admin -c "select * from schema_migrations"version | created_at---------+----------------------------1 | 2017-11-17 13:38:21.055254
The tests
Last but not least, let’s implement a few tests for our app. Let’s start by creating a new script that’s gonna create a database/user for testing (similar to what we did with development database):
dev/init_test_db.sql
;;ALL PRIVILEGES ON DATABASE nerd_recipes_test TO test_user;
and let’s run the script from the command line:
$ psql -U postgres -f dev/init_test_db.sql
Next, create a helper for our tests. It’s gonna run the init function we passed to Drift settings, run all the migrations for us as well as redef the connection to use the test database instead of the development one:
; test/nerd_recipes/test_utils.clj
Now we can test the recipes namespace and verify our functions are working:
Run lein test from the command line and make sure everything passes.
The summary
I hope it was fairly straight forward - please let me know if something was incorrect/unclear by emailing me at [email protected] To clean things up before the next article I’m gonna add the following plugins:
- environ - so we don’t have to hard-code database settings
- cljfmt - to clean up project’s indentation
- auto - to automatically re-run the tests
Next time we’ll actually create a few Compojure routes and add an authentication system.